
自然語言從古至今 Part 2
Published:
第二場的演講比較屬於分享會的形式,內容比較零散,而我只能盡力的整理內容。我覺得重點是要提出一些比較新的概念可以作為大家以後研究方向的入門,讓大家自己去摸索。畢竟要把所有概念講完可能要蠻久的。
NLP 趨勢
從 2013 年開始 NLP 趨勢漸漸從詞向量轉為內容向量 (context vector)
BOW → Doc2Vec → context2vec
1. 2016 context2vec
利用BiLSTM 的模型去學習句子上被屏蔽某些字,設計類似上一篇提到的continuous bag of word (CBOW),透過模型去預測屏蔽掉的字。
這篇論文之後衍生結果 : ELMo → GPT, BERT → MASS, ERNIE, XLNet
2. 2018 ELMo
利用雙向LSTM的隱藏狀態來表達句子向量, 並使用類似 context2vec 預訓練的形式建立個完善的 LM。這裡注意的是預訓練以後,針對其他任務訓練時,它的權重就不會再有更動。
在之後BERT 的論文第9頁提出這種固定權重的方式會限制第二階段的監督學習效果,限制大模型的表現。
3. 2017 Transformer: Attention is all you need
關於 Transformer 的介紹,推薦去看李宏毅的介紹。現場大家都知道機制,所以講者就略過了。
很多介紹文都很詳細的寫了 Transformer 的架構但沒有提到 query x key = weight*value 的概念來源。
$$\alpha(X_{query}, X_{i,key} ) Y_{i, value}$$
講者說目前猜測可能來自1964年的Watson Nadaray 論文。
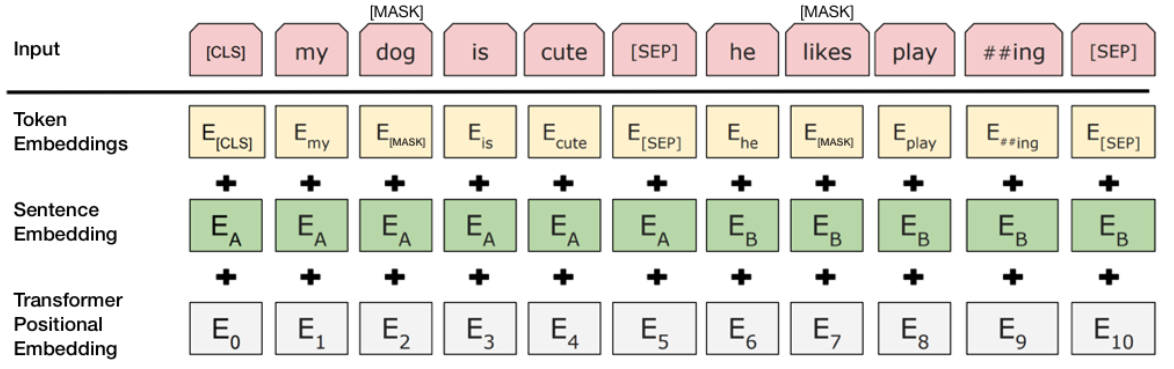
4. 2018 BERT
除了在word 用 MASK,也借鑒 skip-thought 來學習下一個句子的字。實作方法是輸入含兩個句子,句子間以 [SEP] 分割,這兩個句子可能是連貫或不連貫。模型除了需要預測句子間被屏蔽的字,需要學習辨識一個 isNext 或 notNext 的output。
Knowledge Graph in Neural Networks
過去知識圖(KG)的運用往往限制在資料勘探上,隨著自然語言模型表現越來越好,開始有論文將 KG 用在自然語言任務上。
- Entity linking using knowledge graph :
- Growth
- Online learning
- Ontology matching
- knowledge extraction
- Validation
- Error detection
- Entity resolution
- Interface : 2015 lack of a proper interface to interact with KG
- Semantic parsing
- Question answering
- Growth
知識圖的表達 : graph 或類神經表達。然而有沒有方法可以從一個轉去另一種形式呢?
我自己覺得可能 GraphSADE, deepwalk 會有答案?
另外知識圖也可以用在文本生成上,例如 Hearst pattern
Hearst pattern :
NP such as NP, NP, .., and or NP
另外這個方式也可以用文本資料生成知識圖。
Explainable embedding through entity and concept
此外透過向量空間,我們應該可以解釋某個實體與概念之間的關係。例如 IBM 跟 微軟提出相似的實體會有某些共用維度一起被激發。
Coherent Explainable Recommendation [IJCAI 2017]
Handmade vs machine generated KG AAAI 2017
Training KGQA using cQA : generate a template question with a common onthology? ie: what are population of $city/$country/$nation
Entity2Topic NAACL 2018
Introduce ERNIE from thunlp and baidu.
另一種方法是利用翻譯來作為資訊擴充的方式。透過將原始句子翻譯,在一些任務上該語言的空間中比較容易作分割,借此得到比較好的表現。
關於轉移學習,在不同任務間,也許可以使用共用特徵與私人特徵(特徵是針對固定任務學習的)
- Shared-Private Bilingual Word Embeddings for Neural Machine Translation . ACL 2019
時間到 QQ
因為今天內容實在有點零散,許多概念也是點了就跳過,我自己之後再吧缺失的概念慢慢補上去。
OS : 今天尷尬的是作為實驗室的新人,我跟其他成員坐的超遠 QAQ(邊緣人技能正常發揮)。導致開場的自我介紹變得好尷尬。開始前面幾位學生介紹說自己是帥教授的學生,中間穿插黃教授學生再忽然崩出一位帥教授的學生(orz)。啊
另外 教授穿了 2\(\sigma\) (2 sigma)的衣服,感覺好強 (根本與講座沒關係吧)